J’ai toujours été attiré par l’Économie et la Finance, dans leur sens le plus large. Pour moi, elles offrent une lecture globale, structurée et révélatrice d’une situation — que ce soit celle d’un pays, d’une entreprise, ou d’un individu.
Les études en Économie apportent une boîte à outils solide : des méthodes mathématiques et statistiques pour lire, comparer, interpréter ces représentations. On y croise l’économétrie, la macro et la micro-économie, la théorie des jeux …
Autant d’approches rigoureuses, parfaitement adaptées aux cas d’école : les problèmes sont bien définis, les données sont propres, les conclusions logiques.
Mais dès qu’on sort de ce cadre académique, d’autres défis apparaissent :
- Préparer les données :
- compléter via du scraping,
- gérer les données manquantes,
- nettoyer les valeurs aberrantes,
- encoder correctement les variables …
- Régler les algorithmes :
- ajustement des hyperparamètres,
- choix des modèles, etc.
Autant de compétences rarement abordées dans le parcours classique d’un économiste.
C’est là qu’intervient une nouvelle discipline : la data science. Son but est d’extraire un maximum de valeur des données, les transformer en informations utiles pour éclairer les décisions. Le data scientist opère souvent à grande échelle, avec des outils adaptés à la complexité et à l’imperfection du réel.
1. La comparaison entre économiste et data scientist#
Le data scientist (DS) peut être vu comme une évolution naturelle du data analyst (DA). La principale différence tient à l’échelle et à la diversité des données manipulées : là où le DA travaille généralement sur un périmètre ciblé, souvent métier, le DS s’attaque à des ensembles de données massifs et hétérogènes — données commerciales, techniques, comportementales, métadonnées, etc.
Plus globalement, le rôle du data scientist consiste à reformuler un problème métier en un problème mathématique. Il identifie les sources de données pertinentes, les collecte, les traite, et en extrait des enseignements utiles pour orienter les décisions.
Les études en économie s’accordent naturellement avec le métier de data analyst, mais elles offrent aussi une passerelle solide vers celui de data scientist — à condition de compléter la formation initiale sur certains aspects techniques.
Pour devenir data scientist, trois piliers sont essentiels :
- La programmation (Python, R) et la manipulation de bases de données (SQL) ;
- Les mathématiques et la statistique, pour traiter des problématiques de régression, de classification, ou d’optimisation ;
- La communication, indispensable pour bien cerner les besoins métier et rendre les résultats compréhensibles et actionnables.
Le parcours universitaire en économie (LMD en France) forme de bons data analyst, et le passage vers la data science est tout à fait accessible. Les économistes ont déjà l’habitude de modéliser des systèmes complexes — comme un marché — en éléments lisibles et analysables : modèles d’offre et de demande, élasticité, anticipation, etc. Leur objectif est souvent de rendre intelligible une réalité floue, à partir d’outils rigoureux et de concepts théoriques. En ce sens, ils partagent une mission commune avec les data scientists : rendre les données parlantes.
La formation en économie repose en général sur trois piliers :
- La micro et macroéconomie, pour comprendre les dynamiques économiques à différentes échelles grâce à la théorie ;
- Les mathématiques et la statistique, avec un accent sur l’économétrie pour modéliser et tester les relations entre variables ;
- La gestion, avec des bases en comptabilité, finance, management, ou encore politique économique.
À cela s’ajoutent des spécialisations de Master (finance, management, politiques publiques, santé, etc.), qui permettent d’appliquer les concepts à des contextes concrets. C’est en particulier l’économétrie, à la croisée des maths, de la statistique et de la théorie économique, qui constitue le pont naturel avec la data science. Ces deux disciplines se complètent : elles proposent des approches différentes, mais convergentes, pour répondre à des problèmes similaires.
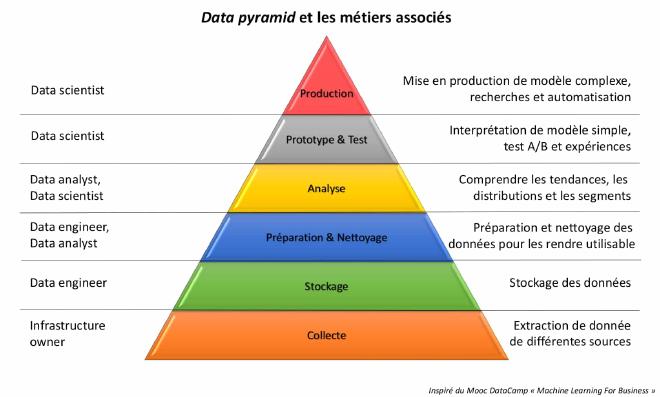
2. Des problématiques différentes mais complémentaires#
Pour illustrer la complémentarité entre l’économie et la science des données, j’ai trouvé un exemple dans le secteur bancaire, avec des solutions utilisables par deux types d’intervenants :
| Économie (causalité) | Data Science (prédiction) | |
|---|---|---|
| Problématique | Quels sont les principaux facteurs qui augmentent le risque de crédit ? | Quel est le meilleur modèle pour prédire le risque de crédit ? |
| Algorithme | Un analyste financier peut identifier des moyens de rééquilibrer un portefeuille en réduisant l’exposition aux facteurs de risque de crédit les plus importants | Un autre analyste peut prédire le risque des nouveaux candidats à l’aide d’un modèle de machine learning |
Cet exemple spécifique traite du secteur bancaire, mais cette complémentarité s’étend à d’autres domaines : assurance, santé, politiques publiques, recherche, etc.
La complémentarité des deux métiers est très attrayante pour identifier les besoins des clients et y répondre avec précision. Les économistes-data-scientists ont l’habitude de travailler dans ces domaines, ils connaissent les enjeux et sont formés pour les interpréter, ce qui leur confère un avantage et une forte valeur ajoutée.
Ce double rôle leur permet de faire la distinction entre les questions d’inférence et de prédiction, et de choisir la méthode d’analyse adéquate en fonction des besoins de l’entreprise.
3. Avec des compétences déjà acquises#
D’un point de vue technique, on part aussi avec de solides bases pour aborder la data science. Beaucoup de méthodes utilisées en machine learning sont en réalité des extensions ou des généralisations d’outils déjà vus en économie :
- De nombreux algorithmes reposent sur des régressions linéaires ou logarithmiques, familières à tout étudiant en économétrie ;
- Les réseaux de neurones peuvent être vus comme une empilement de régressions logistiques, permettant de capturer des relations non linéaires complexes ;
- La notion d’hétéroscédasticité — centrale dans l’analyse économétrique — se retrouve dans les machines à vecteurs de support (SVM) et d’autres modèles.
Côté programmation, j’étais déjà à l’aise avec R et SAS durant mes études, ce qui m’a permis de passer facilement à Python et SQL.
Pour aller plus loin, je me suis aussi formé aux méthodes de data science via des MOOCs, la plupart sont gratuits.
Aujourd’hui, certains Masters proposent des doubles cursus “Économie & Data Science” — comme l’ENSAE qui forme des “data strategists” — et de plus en plus de diplômes universitaires (DU) sortent du lot avec une spécialisation claire. Ces évolutions montrent que ces métiers s’adaptent au monde numérique, et qu’avoir cette double casquette devient un vrai levier, à la fois pour l’individu et pour l’entreprise.
4. Ce que j’en retiens#
Se spécialiser en data science quand on vient de l’économie, c’est s’ouvrir à des méthodes innovantes, rigoureuses, et souvent complémentaires. L’effort pour acquérir les compétences techniques est relativement limité — surtout quand on a déjà une appétence pour l’analyse.
Mais surtout, cette montée en compétence apporte une réelle valeur ajoutée : elle permet de mieux comprendre les problématiques business, de mieux structurer les réponses aux enjeux stratégiques, et d’accompagner les décisions sur des bases solides, éclairées par les données.
Références#
- Big Data : économie et régulation, Enjeux numériques, N°2 - Juin 2018, Annales des Mines
- La famille des Data Scientists s’agrandit : bienvenue au data scientist économiste !