1. Introduction#
Le théorème de CAP est souvent évoqué dans le domaine des bases de données distribuées, mais il est parfois perçu comme un concept abstrait ou réservé aux ingénieurs systèmes. Pourtant, il s’agit avant tout d’un principe de conception qui aide à comprendre pourquoi un système ne peut pas tout faire à la fois.
CAP signifie Cohérence (Consistency), Disponibilité (Availability) et Tolérance au Partitionnement (Partition tolerance). Ces trois propriétés définissent les priorités possibles d’un système distribué lorsque des défaillances surviennent.
2. Les trois piliers du CAP#
Cohérence (Consistency)
Chaque nœud du système doit présenter la même version des données à tout instant. Si un client lit après une écriture, il doit obtenir la dernière valeur écrite.
→ Exemple : un compte bancaire mis à jour sur un serveur doit immédiatement refléter le même solde sur tous les serveurs.Disponibilité (Availability)
Le système doit répondre à chaque requête (lecture ou écriture), même si une partie du système est en panne.
→ Exemple : Amazon ou Netflix ne peuvent pas se permettre qu’un utilisateur voie une page d’erreur juste parce qu’un serveur est déconnecté.Tolérance au Partitionnement (Partition Tolerance)
Le système doit continuer à fonctionner malgré une perte temporaire de communication entre ses composants.
→ Exemple : deux datacenters séparés géographiquement peuvent perdre la connexion sans que tout s’arrête.
3. Le théorème de Brewer : impossible d’avoir les trois#
Le théorème de CAP, formulé par Eric Brewer et démontré par Seth Gilbert et Nancy Lynch (MIT), énonce qu’un système distribué ne peut garantir simultanément les trois propriétés CAP.
En cas de panne réseau (partitionnement), il faut choisir entre :
- Cohérence et Tolérance au partitionnement (CP)
→ le système reste cohérent, mais certaines requêtes échouent. - Disponibilité et Tolérance au partitionnement (AP)
→ le système reste disponible, mais les données peuvent être momentanément incohérentes.
Ainsi, le CAP ne dit pas « qu’on ne peut jamais avoir les trois », mais qu’en cas de problème réseau, un choix de priorité doit être fait.
4. Démonstration#
Prenons un exemple simplifié avec deux serveurs : A et B, qui stockent une même donnée :
compte = 100€
Une défaillance réseau survient : A et B ne peuvent plus communiquer.
Cas 1 – Cohérence prioritaire (CP)
Le serveur A refuse toute écriture tant qu’il n’est pas sûr que B ait reçu la mise à jour.
→ Les données restent cohérentes (même valeur sur A et B), mais les utilisateurs peuvent recevoir une erreur ou attendre longtemps.
→ Exemple typique : bases de données relationnelles comme PostgreSQL en mode cluster strict.Cas 2 – Disponibilité prioritaire (AP)
A et B acceptent chacun des écritures locales, même sans se synchroniser.
→ Le système reste disponible, mais les valeurs peuvent diverger temporairement.
→ Exemple typique : Cassandra ou DynamoDB, qui préfèrent la disponibilité et effectuent une réconciliation ultérieure (eventual consistency).
Dans les deux cas, un compromis est fait entre cohérence et disponibilité, selon la nature de l’application.
5. Représentation graphique#
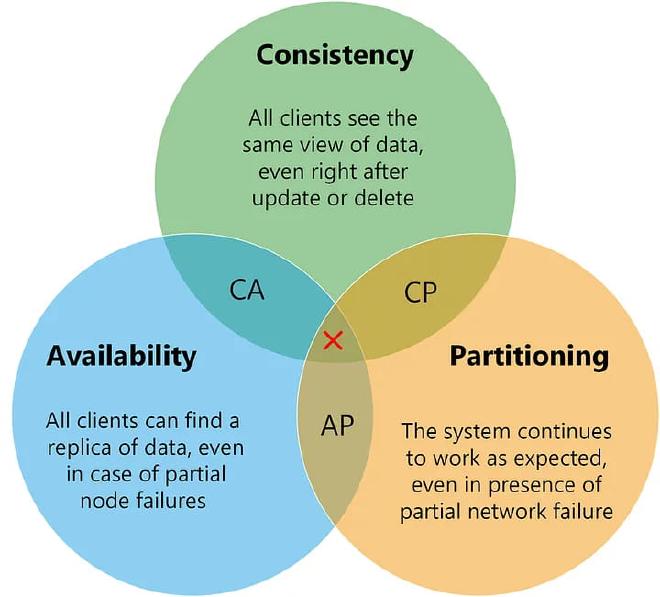
Chaque système se situe entre deux sommets, selon les priorités choisies.
Il est souvent noté qu’un système « AP » ou « CP » ne renonce pas totalement à la troisième propriété, mais en fait une priorité secondaire.
| Type de système | Priorités | Exemple |
|---|---|---|
| CP (Cohérence + Partition) | La cohérence prime, la disponibilité peut être sacrifiée | MongoDB (en mode strict), HBase |
| AP (Disponibilité + Partition) | La réponse rapide prime, même si la donnée n’est pas à jour | Cassandra, CouchDB, DynamoDB |
| CA (Cohérence + Disponibilité, sans partition) | Possible uniquement sur un seul nœud ou réseau local | PostgreSQL, MySQL classiques |
6. Application pour un data scientist / data engineer#
Dans la pratique, le théorème de CAP aide à :
- choisir une base adaptée au besoin (par ex. Cassandra pour la scalabilité et la tolérance, PostgreSQL pour la cohérence forte) ;
- concevoir des pipelines robustes, où certains traitements peuvent tolérer des retards (eventual consistency) ;
- comprendre les limites de la réplication et du partitionnement dans les architectures distribuées (Kafka, Spark, etc.).
Il ne s’agit donc pas d’une règle rigide, mais d’un cadre de réflexion sur la manière de gérer les pannes et la cohérence des données.
7. Conclusion#
Le théorème de CAP rappelle qu’un système distribué est avant tout un compromis. Aucun choix n’est parfait : tout dépend du contexte.
Certaines architectures privilégient la fiabilité des données, d’autres la continuité de service.
L’essentiel est de comprendre ce que l’on sacrifie, plutôt que d’espérer concilier les trois propriétés simultanément.