Cela fait un moment que je postule à des postes généralistes en data science. Un métier longtemps présenté comme “le plus sexy du 21e siècle”… mais qui semble avoir connu un certain réajustement ces dernières années.
Depuis la crise du Covid, les entreprises ont pris conscience d’un enjeu fondamental : avant de produire des modèles, encore faut-il disposer de données fiables, structurées et exploitables. Résultat : le marché tend à valoriser davantage les compétences en data engineering, avec une recrudescence d’offres centrées sur l’ingestion, le traitement et l’architecture des données.
C’est dans ce contexte que je suis tombé sur un article de Mikael El Ouazzani, qui a eu l’idée intéressante de créer un observatoire des métiers de la data. Le principe : comparer ce que le marché demande avec ce que nous, professionnels, avons à offrir, pour en déduire une position relative.
1. Tout d’abord, qu’est-ce que j’ai à offrir ?#
Selon les missions, je peux porter trois casquettes différentes :
| Data Scientist | extraire de l’information et des insights à partir de données structurées ou non, en combinant des techniques statistiques, mathématiques et informatiques | mathématiques statistiques Python R pandas numpy scipy scikit-learn tensorflow keras pytorch |
| Data Engineer | construire des infrastructures et des architectures solides pour l’acquisition, le stockage, la transformation et la distribution des données | Python SQL Airflow ETL Spark Talend SQL/NoSQL Cloud (AWS, GCP, Azure) |
| Dév. Python back-end | gérer la partie serveur d’applications web, optimiser les performances du back-end, les bases de données et la logique métier | Python Flask/Django PostgreSQL MySQL MongoDB API REST DevOps Docker Kubernetes pipelines CI/CD |
Voyons maintenant ce qui colle le mieux entre mon profil et les attentes du marché…
2. À la pêche aux données avec un peu de rétro-ingénierie#
Pour creuser tout ça, je suis allé chercher des infos sur différentes plateformes d’offres d’emploi, d’abord en France, puis à l’international.
Quand on navigue sur un site ou une application, énormément d’informations circulent en arrière-plan via les fameuses APIs (interfaces de programmation). J’ai analysé le fonctionnement de certaines applications et sites pour accéder aux données échangées avec leurs serveurs.
En observant ces requêtes, on peut comprendre la structure des données utilisées et les reproduire pour collecter de l’information en masse, sans avoir à cliquer manuellement sur chaque offre. C’est ce qu’on appelle de la rétro-ingénierie d’appels API.
Je vois trois gros avantages à cette approche :
- Des données plus riches : celles accessibles via API sont souvent mieux structurées et plus complètes que celles qu’on obtient en scrappant les pages HTML. On y trouve aussi des métadonnées, des filtres de recherche, ou encore des infos non affichées à l’écran.
- L’automatisation : une fois le fonctionnement des appels API compris, on peut automatiser la collecte et suivre l’évolution du marché en temps réel ou à fréquence régulière.
- L’efficacité : ça évite de passer par des systèmes de scraping visuel plus lents et fragiles, souvent cassés au moindre changement de mise en page du site.
Je ne vais pas détailler ici les techniques concrètes car la doc est déjà bien fournie sur le sujet.
Pour ne pas noyer l’analyse et garder des résultats exploitables, j’ai filtré les offres contenant les mots-clés data, python et react.
On passe maintenant à la sélection des données !
3. Sélection, nettoyage et enrichissement des données#
Comme expliqué dans la partie précédente, les APIs renvoient des données déjà structurées, généralement au format JSON. Ça facilite grandement la sélection des variables pertinentes.
Pour cette première version de l’observatoire, j’ai choisi de me concentrer sur les éléments suivants :
- secteur d’activité
- intitulé du poste
- compétences requises
- compétences appréciées
- salaire
- localisation
L’API fournit également des slugs, des identifiants uniques, qui permettent d’uniformiser les données. Voici, par exemple, les 5 slugs les plus fréquents dans mes résultats :
ingenieur-dataanalystedata-managerdeveloppeur-pythondeveloppeur-web
Pour faciliter l’analyse, j’ai créé une classification personnalisée :
classification_dict = {
'data_scientist': [
'ingenieur-data', 'data-scientist',
'ingenieur-de-recherche-machine-learning'
],
'business_analyst': [
'analyste', 'analyste-programmeur',
'consultant', 'consultant-erp-systems',
'consultant-bi', 'consultant-moa',
'product-owner', 'consultant-fonctionnel',
'assistant-fonctionnel'
],
'data_engineer': [
'consultant-en-architecture', 'architecte',
'architecte-technique', 'architecte-si',
'architecte-systeme', 'architecte-base-de-donnees',
'ingenieur-devops', 'administrateur-sql',
'ingenieur-dintegration', 'administrateur-bdd',
'developpeur-oracle', 'administrateur-linux',
'administrateur-erp', 'ingenieur-de-developpement',
'administrateur-reseaux', 'architecte-base-de-donnees'
],
'development': [
'developpeur', 'developpeur-java', 'api-developpeur',
'developpeur-python', 'lead-developer',
'developpeur-oracle', 'developpeur-php',
'developpeur-web', 'developpeur-salesforce'
],
'project_management': [
'assistant-chef-de-projet', 'data-manager',
'scrum-master', 'coach-agile', 'chef-de-projet',
'directeur-de-projet', 'responsable-technique',
'responsable-dexploitation',
'project-manager-web-e-commerce',
'chef-de-projet-e-commerce'
],
'other': [
'autre', 'marketing-e-commerce',
'consultant-microsoft-dynamics',
'consultant-securite-et-reseaux', …
]
}
Voici donc les grandes familles de métiers qui ressortent de mon analyse.
Sur la plupart des sites d’emploi, aucune distinction claire n’est faite entre développeurs Python back-end et front-end. C’est quelque chose qui peut être améliorer en analysant le contenu des descriptions de poste.
4. Analyse exploratoire des données (EDA) et premières interprétations#
À la date du 23 juillet 2024, avec ce premier recensement, j’ai récolté une base de 1 217 offres distinctes, majoritairement dans le secteur de la data, et centrées sur le territoire français.
Mon analyse est en coupe instantanée : faute de données sur le long terme (le projet est encore jeune), je ne peux pas encore tirer de tendances temporelles solides.
Les offres recensées ont été publiées entre le 8 mars 2024 et le 23 juillet 2024. Une visualisation de leur répartition temporelle sera ajoutée plus tard.
En attendant, voici déjà une première répartition des différentes catégories de postes :
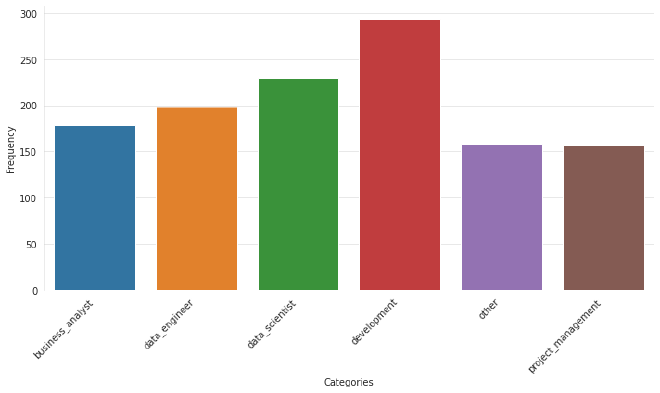
Si je me limite aux mots-clés data, python et react
- On remarque que les offres liées au développement d’applications sont clairement en tête
- En deuxième position, et presque de manière surprenante, on trouve la data science. Je dis “surprenante”, car je m’attendais à voir davantage de postes côté data engineering ou business analyst. Ce résultat est peut-être biaisé par ma classification simplifiée.
Voyons maintenant quelles sont les compétences les plus demandées dans les offres filtrées.
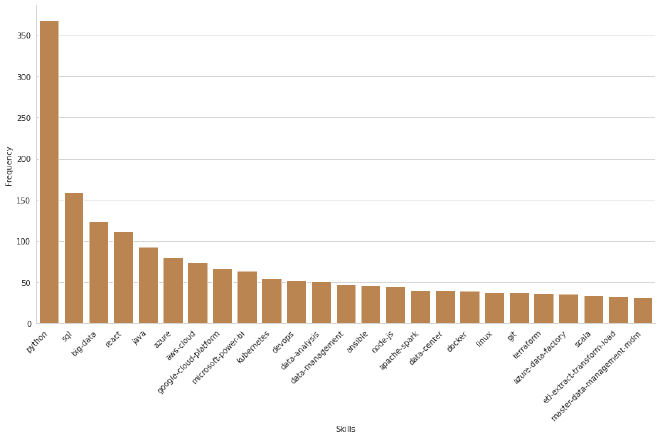
- Sans surprise :
Pythonécrase tout. Ce langage polyvalent est présent dans un grand nombre de métiers, ce qui pourrait justifier une analyse plus fine côté bibliothèques spécifiques (ça parlerait beaucoup plus). - On observe aussi des “compétences” qui n’en sont pas vraiment :
data-analysis,data-management,data-center,master-data-management-mdm! Il va falloir faire un peu de ménage pour affiner les prochaines analyses.
On pousse un peu plus loin l’exploration avec des analyses factorielles.
Je switche mon kernel Python pour un kernel R, car je suis bien plus à l’aise avec ce genre de traitements statistiques avancés.
L’analyse porte sur un tableau de contingence. Pour une meilleure lisibilité, j’ai mis de côté les catégories “autre” et “project_management”, moins intéressantes ici. Je n’ai conservé que les 10 compétences les plus représentées par catégorie. Certaines apparaissent plusieurs fois, ce qui nous donne au final 24 compétences différentes.
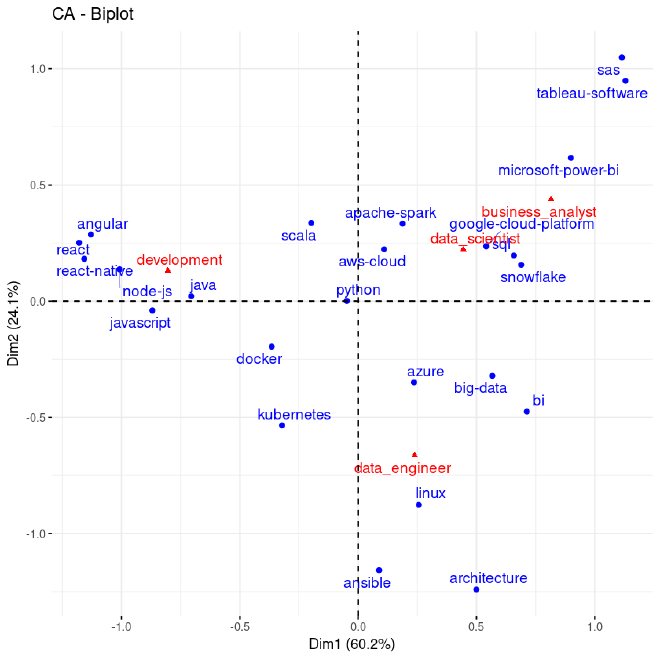
Quelques enseignements ressortent clairement :
Python se retrouve au centre du graphique — sans surprise, puisque c’est une compétence attendue dans tous les métiers. Elle est donc peu discriminante.
Les métiers de data scientist et de business analyst sont très proches, ce qui confirme une critique fréquente : il est parfois difficile, même pour les recruteurs, de bien distinguer les deux rôles.
Les compétences se répartissent assez nettement selon les métiers :
- Le data scientist, quant à lui, est lié à
Spark, un peu decloud, duSQL,Snowflake - Le data engineer est plus orienté infrastructure :
Linux,architecture,Ansible,cloud computing - Le développeur utilise des outils comme
React,Java,JavaScript,Angular - Le business analyst se tourne vers les outils de visualisation comme
Power BI,Tableau
- Le data scientist, quant à lui, est lié à
5. Et maintenant ?#
Voici quelques idées que j’aimerais explorer dans la suite du projet :
- Une analyse cartographique des offres (avec QGIS)
- Une analyse temporelle, dès que j’aurai assez de données pour en tirer quelque chose de solide
- Une analyse plus fine des descriptifs de poste, éventuellement enrichie par des analyses avec LLM